jusText

jusText is a library for removing boilerplate content, such as navigation links, headers, and footers from HTML pages. It is designed to preserve mainly text containing full sentences and it is therefore well suited for creating linguistic resources such as Web corpora.
The algorithm is largely based on Jan Pomikálek's PhD thesis and its original Python-based implementation.
Introduction
The algorithm uses a simple way of segmentation. The contents of some HTML tags are (by default) visually formatted as
blocks by Web browsers. The idea is to form textual blocks by splitting the HTML page on these tags. The full list of
the used block-level tags includes: BLOCKQUOTE, CAPTION, CENTER, COL, COLGROUP, DD, DIV, DL, DT,
FIELDSET, FORM, H1, H2, H3, H4, H5, H6, LEGEND, LI, OPTGROUP, OPTION, P, PRE, TABLE, TD,
TEXTAREA, TFOOT, TH, THEAD, TR, UL. A sequence of two or more BR tags also separates blocks.
Though some of such blocks may contain a mixture of good and boilerplate content, this is fairly rare. Most blocks are homogeneous in this respect.
Several observations can be made about such blocks:
- Short blocks which contain a link are almost always boilerplate.
- Any blocks which contain many links are almost always boilerplate.
- Long blocks which contain grammatical text are almost always good whereas all other long block are almost always boilerplate.
- Both good (main content) and boilerplate blocks tend to create clusters, i.e. a boilerplate block is usually surrounded by other boilerplate blocks and vice versa.
Deciding whether a text is grammatical or not may be tricky, but a simple heuristic can be used based on the volume of function words (stop words). While a grammatical text will typically contain a certain proportion of function words, few function words will be present in boilerplate content such as lists and enumerations.
The key idea of the algorithm is that long blocks and some short blocks can be classified with very high confidence. All the other short blocks can then be classified by looking at the surrounding blocks.
Pre-processing
In the pre-processing stage, the contents of HEAD, META, TITLE, SCRIPT, STYLE tags are removed along with
comments, DOCTYPE and XML declarations. The contents of SELECT tags are immediately labeled as bad
(boilerplate). The same applies to blocks containing a copyright symbol (©).
Classification
Context-free classification
After the segmentation and pre-processing, context-free classification is executed which assigns each block to one of four classes:
BAD- boilerplate blocksGOOD- main content blocksSHORT- too short to make a reliable decision about the classNEAR_GOOD- somewhere in-betweenSHORTandGOOD
The classification is done by the following algorithm:
static Classification doClassifyContextFree(
Paragraph paragraph,
Set<String> stopWords,
ClassifierProperties classifierProperties) {
// Boilerpate blocks
if (paragraph.isImage()) {
return BAD;
}
if (paragraph.getLinkDensity() > classifierProperties.getMaxLinkDensity()) {
return BAD;
}
String text = paragraph.getText();
if (StringUtil.contains(text, COPYRIGHT_CHAR) || StringUtil.contains(text, COPYRIGHT_CODE)) {
return BAD;
}
// Classfify headlines as good
if (!classifierProperties.getNoHeadlines() && paragraph.isHeadline()) {
return GOOD;
}
if (paragraph.isSelect()) {
return BAD;
}
int length = paragraph.length();
// Short blocks
if (length < classifierProperties.getLengthLow()) {
if (paragraph.getCharsInLinksCount() > 0) {
return BAD;
}
return SHORT;
}
float stopWordsDensity = paragraph.getStopWordsDensity(stopWords);
// Medium and long blocks
if (stopWordsDensity >= classifierProperties.getStopWordsHigh()) {
if (length > classifierProperties.getLengthHigh()) {
return GOOD;
}
return NEAR_GOOD;
}
if (stopWordsDensity >= classifierProperties.getStopWordsLow()) {
return NEAR_GOOD;
}
return BAD;
}The length is the number of characters in the block. The link density is defined as the proportion of characters inside
A tags. The stop words density is the proportion of stop list words (the text is tokenized into "words" by splitting
at spaces).
The algorithm takes five parameters integers lengthLow, lengthHigh, maxLinkDensity, stopWordsLow and
stopWordsHigh. The former two set the thresholds for dividing the blocks by length into short, medium-size and long.
The latter two divide the blocks by the stop words density into low, medium and high. The default settings are:
maxLinkDensity= 0.2lengthLow= 70lengthHigh= 200stopWordsLow= 0.30stopWordsHigh= 0.32
These values give good results with respect to creating textual resources for corpora. They have been determined by performing a number of experiments.
| Block size (word count) | Stopwords density | Classification |
|---|---|---|
| medium | low | BAD |
| long | low | BAD |
| medium | medium | NEAR_GOOD |
| long | medium | NEAR_GOOD |
| medium-size | high | NEAR_GOOD |
| long | high | GOOD |
Context-sensitive classification
The goal of the context-sensitive part of the algorithm is to re-classify the SHORT and NEAR_GOOD blocks either as
GOOD or BAD based on the classes of the surrounding blocks. The blocks already classified as GOOD or BAD serve
as the baseline in this stage. Their classification is considered reliable and is never changed.
The pre-classified blocks can be viewed as sequences of SHORT and NEAR_GOOD blocks delimited with GOOD and BAD
blocks. Each such sequence can be surrounded by two GOOD blocks, two BAD blocks or by a GOOD block at one side and
a BAD block at the other.
The former two cases are handled easily. All blocks in the sequence are classified as GOOD or BAD respectively.
In the latter case, a NEAR_GOOD block closest to the BAD block serves as a delimiter of the GOOD and BAD area.
All blocks between the BAD block and the NEAR_GOOD block are classified as BAD.
All the others are classified as GOOD. If all the blocks in the sequence are short (there is no NEAR_GOOD block)
they are all classified as BAD. This is illustrated on the following example:
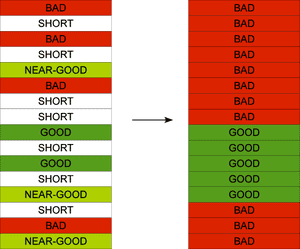
The idea behind the context-sensitive classification is that boilerplate blocks are typically surrounded by other
boilerplate blocks and vice versa. The NEAR_GOOD blocks usually contain useful corpus data if they occur close to
GOOD blocks. The SHORT blocks are typically only useful if they are surrounded by GOOD blocks from both sides.
They may, for instance, be a part of a dialogue where each utterance is formatted as a single block.
While discarding them may not constitute a loss of significant amount of data, losing the context for the remaining
nearby blocks could be a problem.
In the description of the context-sensitive classification, one special case has been intentionally omitted in order to
keep it reasonably simple. A sequence of SHORT and NEAR_GOOD blocks may as well occur at the beginning or at the end
of the document. This case is handled as if the edges of the documents were bad blocks as the main content is typically
located in the middle of the document and the boilerplate near the borders.
Headings
Header blocks (those enclosed in H1, H2, H3, etc. tags) are treated in a special way unless the noHeadings
option is used. The aim is to preserve headings for the GOOD texts. Within that H1 can be classified as always
GOOD, unless the noHeadline option is used.
The algorithm adds two stages of processing for the header blocks. The first stage (pre-processing) is executed after context-free classification and before context-sensitive classification. The second stage (post-processing) is performed after the context-sensitive classification:
- context-free classification
- pre-processing of header blocks
- context-sensitive classification
- post-processing of header blocks
The pre-processing looks for SHORT header blocks which precede GOOD blocks and at the same time there is no more
than maxHeadingDistance characters between the header block and the GOOD block. The context-free class of such
header blocks is changed from SHORT to NEAR_GOOD. The purpose of this is to preserve SHORT blocks between the
heading and the GOOD text which might otherwise be removed (classified as bad) by the context-sensitive
classification.
The post-processing again looks for header blocks which precede GOOD blocks and are no further than
maxHeadingDistance away. This time, the matched headers are classified as GOOD if their context-free class was other
was not BAD. In other words, BAD headings remain BAD, but some SHORT and NEAR_GOOD headings can be classified
as GOOD if they precede GOOD blocks, even though they would normally be classified as BAD by the context-sensitive
classification (e.g. they are surrounded by bad blocks). This stage preserves the "non-bad" headings of good blocks.
Note that the post-processing is not iterative, i.e. the header blocks re-classified as GOOD do not affect the
classification of any other preceding header blocks.