GDPR forget-me app (Part 2): Messaging with Spring Integration and AMQP

This second part focuses on how to use Java DSL for defining in- and outbound messaging with Spring Integration’s AMQP support. Java DSL is now (as of version 5) part of Spring Integration's core project and doesn’t have be included as a separate dependency. Altought sending and receiving messages to RabbitMQ doesn't necessarily appear to be complicated at a first glance, there are pitfalls you might run into.
In the first part of this series, I defined only the requirements, mainly as a guideline and future reference for myself and I also wanted to see if there's an interest in such an app within community of tech bloggers. As there seems to be an interest in such a system, in part two and onwards we'll take closer looks into implementation details. Particularly, one of the actual message flows of the app will be under a microscope in this part.
Pitfalls of in- and outbound messaging with AMQP
There will be two challenges you'll face when you try to send and receive messages from/to RabbitMQ with Spring Integration.
#1 Message ID and Timestamp
Spring Integration populates two standard message headers, namely ID (with a random UUID) and TIMESTAMP
(with milliseconds elapsed since the Epoch). It's quite natural to expect that these headers values will be exactly the
same when the message is sent and when it's received.
With the default Spring AMQP setup however, the received message won't have an ID and TIMESTAMP. This is going
to change as of 5.1 M1 thanks to
Gary Russel, who responded to my improvement request
(INT-4476) very quickly.
#2 Poison Messages
When the consumer is unable to process an incoming message from the queue and raises an error, the same message will be re-queued and redelivered again by default. Altought it does make sense to retry delivery sometimes, in case of receiving a poison message, the system might come to a halt, as it's repeatedly trying to deliver the very same bad message every time. As redelivering messages can be implemented by both Spring AMQP and Spring Retry, the first thing you need to understand is which components is performing undesirable infinite retry.
Message flow
Let's get back to the forget-me app and dive into that message flow
which is responsible for processing incoming events emitted by 3rd party systems. There are cloud-based services
providing various solutions for bloggers like email marketing automation (eg. MailerLite
or Drip), online course hosting (eg. Teachable), etc.
All of those providers, the app is going to support in version 0.1, emit notifications upon the occurrence of
certain events. They do that by using webhooks. The forget-me app keeps these subscription related events on record,
in order to be able to show a subscriber where their personal data is stored. Note that the app itself doesn't store
any kind of personal data, even the subscriber's email address is stored in a strongly hashed format.
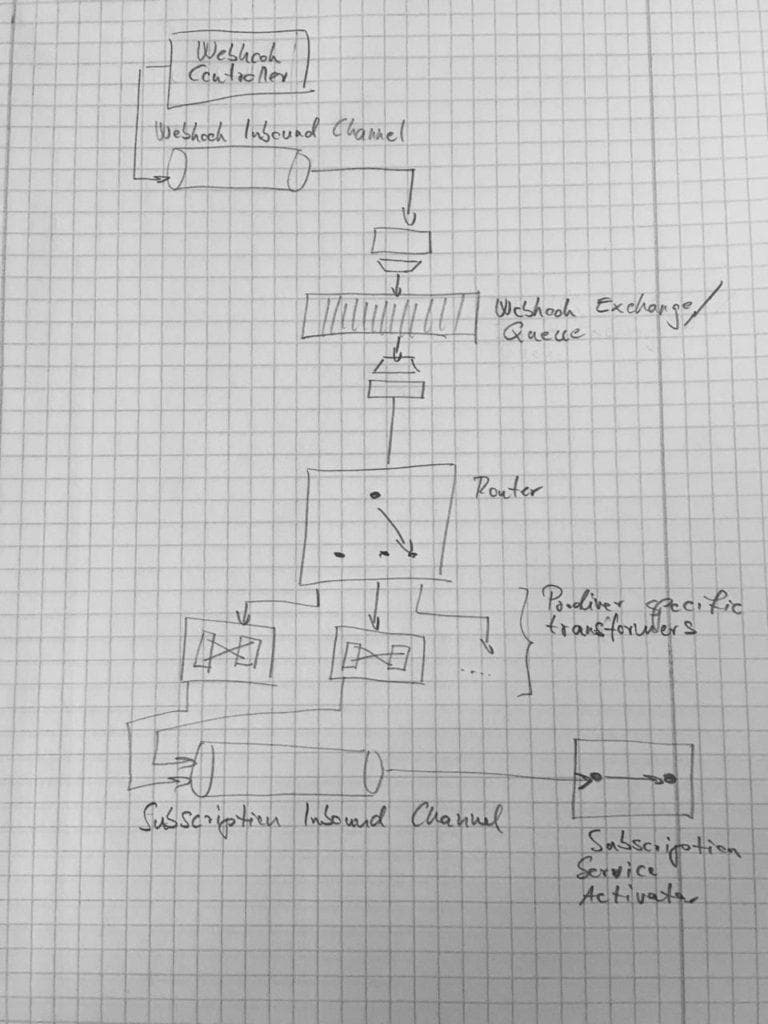
Webhook controller
The source of the message flow is a standard REST controller that is responsible for receiving notification data on
/webhook/{datahandler_id}/{datahandler_key}. At this point the only requirement against the incoming data is that it
must be a JSON document. The actual data format varies widely, thus in this phrase we just accept whatever the
underlying data provider has sent and it's going to be parsed later.
@Controller
public class WebhookController {
private final WebhookService webhookService;
public WebhookController(WebhookService webhookService) {
this.webhookService = webhookService;
}
@PostMapping(
path = "/webhook/{dataHandlerId}/{dataHandlerKey}",
consumes = APPLICATION_JSON_VALUE
)
public HttpEntity submitData(
@PathVariable UUID dataHandlerId,
@PathVariable UUID dataHandlerKey,
@RequestBody Map<String, Object> jsonData) {
webhookService.submitData(dataHandlerId, dataHandlerKey, jsonData);
return ResponseEntity.accepted().build();
}
} Fortunately it's enough to define that we expect application/json as the Content-Type of the request's body and
Spring MVC's built-in
HttpMessageConverters
take care of the rest.
Webhook Inbound Channel
We would like components to be as independent of the actual infrastructure as they can be, thus the app relies heavily
on Spring Integration's MessageChannel abstraction,
which is a means of decoupling components from each other. Instead of using
RabbitTemplate
(or its counterparts like JmsTemplate,
etc.) directly, an outbound message flow is defined that is terminated by an
AMQP outbound adapter.
@Configuration
public class WebhookFlowConfig {
@Bean
public MessageChannel webhookOutboundChannel() {
return new DirectChannel();
}
@Bean
public IntegrationFlow webhookOutboundFlow(
MessageChannel webhookOutboundChannel, EventHeadersValueGenerator eventHeadersValueGenerator,
AmqpTemplate amqpTemplate) {
return IntegrationFlows.from(webhookOutboundChannel)
.enrich(e -> e
.headerFunction(EVENT_ID, eventHeadersValueGenerator::createEventId)
.headerFunction(EVENT_TIMESTAMP, eventHeadersValueGenerator::createEventTimestamp)
)
.transform(Transformers.toJson())
.handle(Amqp.outboundAdapter(amqpTemplate).exchangeName(FORGETME_WEBHOOK_EXCHANGE_NAME)
.routingKey(FORGETME_WEBHOOK_ROUTING_KEY_NAME))
.get();
}
...
}Webhook Exchange, Message and Dead Letter Queues
Data providers usually implement a retry mechanism to resend data, should your webhook fail to accept it. While this is undoubtedly useful, we can't expect a single standard behvaiour from that many cloud-based services. Therefore, whatever data is received, it's put into a message queue for further processing and webhook controller just returns HTTP 202 (Accepted). According to Murph's law, what can happen will happen. There might be API changes or simply bad data sent and which case we would like to gather un-processable messages for further inspection. Most message brokers do support dead lettering and fortunately RabbitMQ is no exception.
@Configuration
public class QueueConfig {
public static final String FORGETME_WEBHOOK_EXCHANGE_NAME = "forgetme-webhook.exchange";
public static final String FORGETME_WEBHOOK_DEAD_LETTER_EXCHANGE_NAME =
"forgetme-webhook.dead-letter.exchange";
public static final String FORGETME_WEBHOOK_QUEUE_NAME = "forgetme-webhook.queue";
public static final String FORGETME_WEBHOOK_DEAD_LETTER_QUEUE_NAME =
"forgetme-webhook.dead-letter.queue";
public static final String FORGETME_WEBHOOK_ROUTING_KEY_NAME = "forgetme-webhook";
/// WEBHOOK ///
@Bean
public DirectExchange forgetmeWebhookExchange() {
return new DirectExchange(FORGETME_WEBHOOK_EXCHANGE_NAME);
}
@Bean
public DirectExchange forgetmeWebhookDeadLetterExchange() {
return new DirectExchange(FORGETME_WEBHOOK_DEAD_LETTER_EXCHANGE_NAME);
}
@Bean
public Queue forgetmeWebhookQueue() {
return QueueBuilder
.durable(FORGETME_WEBHOOK_QUEUE_NAME)
.withArgument("x-dead-letter-exchange", FORGETME_WEBHOOK_DEAD_LETTER_EXCHANGE_NAME)
.build();
}
@Bean
public Queue forgetmeWebhookDeadLetterQueue() {
return QueueBuilder.durable(FORGETME_WEBHOOK_DEAD_LETTER_QUEUE_NAME).build();
}
@Bean
public Binding forgetmeWebhookBinding(
DirectExchange forgetmeWebhookExchange,
Queue forgetmeWebhookQueue) {
return BindingBuilder
.bind(forgetmeWebhookQueue)
.to(forgetmeWebhookExchange)
.with(FORGETME_WEBHOOK_ROUTING_KEY_NAME);
}
@Bean
public Binding forgetmeWebhookDeadLetterBinding(
DirectExchange forgetmeWebhookDeadLetterExchange,
Queue forgetmeWebhookDeadLetterQueue) {
return BindingBuilder
.bind(forgetmeWebhookDeadLetterQueue)
.to(forgetmeWebhookDeadLetterExchange)
.with(FORGETME_WEBHOOK_ROUTING_KEY_NAME);
}
...
}When there's an error, the faulty message ends up being delivered to a dead letter queue. I'll elaborate more on retry and handling poison messages below.
Pre-transform
All we know of incoming message is that they're supposed have JSON payloads. Adherence to a fixed schema cannot be
expected due the variety of providers. Hence in the phrase of transformation, which is common for all the providers,
the incoming JSON is transformed to a
JsonNode
instance.
public class ObjectToJsonNodeTransformer implements GenericTransformer<Object, JsonNode> {
private final ObjectMapper objectMapper;
@Override
public JsonNode transform(Object json) {
if (json == null) {
return null;
}
try {
if (json instanceof String) {
return this.objectMapper.readTree((String) json);
} else if (json instanceof byte[]) {
return this.objectMapper.readTree((byte[]) json);
} else if (json instanceof File) {
return this.objectMapper.readTree((File) json);
} else if (json instanceof URL) {
return this.objectMapper.readTree((URL) json);
} else if (json instanceof InputStream) {
return this.objectMapper.readTree((InputStream) json);
} else if (json instanceof Reader) {
return this.objectMapper.readTree((Reader) json);
} else {
throw new IllegalArgumentException("unsupported argument class: " + json.getClass());
}
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}Jackson's ability to pre-process documents to a tree of JsonNode is very handy for this use case. Later on downstream
(provider specific) transformers start from the root of such a JSON tree, traverse it by looking for values along
various paths.
Message Routing
Upon receiving the incoming data via the webhook, the data provider's UUID is resolved to it's name and stored as a message header.
@Service
public class WebhookServiceImpl implements WebhookService {
private final DataHandlerRepository dataHandlerRepository;
private final MessageChannel webhookOutboundChannel;
public WebhookServiceImpl(
DataHandlerRepository dataHandlerRepository,
MessageChannel webhookOutboundChannel) {
this.dataHandlerRepository = dataHandlerRepository;
this.webhookOutboundChannel = webhookOutboundChannel;
}
@Override
@Transactional
public void submitData(UUID dataHandlerId, UUID key, Map<String, Object> data) {
DataHandler dataHandler = dataHandlerRepository
.findById(dataHandlerId)
.orElseThrow(() -> new EntityNotFoundException("id", dataHandlerId));
// For security reasons, it's safer to throw EntityNotFoundException, which will be exposed as
// HTTP 404, so that an attacker couldn't differentiate a non-existent ID from a bad key.
if (!dataHandler.getKey().equals(key)) {
throw new EntityNotFoundException("key", key);
}
Message<Map<String, Object>> message = MessageBuilder
.withPayload(data)
.setHeader(DATA_HANDLER_ID, dataHandlerId)
.setHeader(DATA_HANDLER_NAME, dataHandler.getName())
.build();
webhookOutboundChannel.send(message);
}
}Addressing pitfall #1: Message ID and Timestamp

Currently AbstractHeaderMapper declares MessageHeaders.ID and MessageHeaders.TIMESTAMP as transient fields.
As a consequence, when a message gets sent through an AMQP outbound adapter, the value of these two fields gets discarded.
Although IDs could be fixed by turning on implicit ID generation on the descendants of AbstractMessageConverter (setting createMessageIds=true), that comes with a side effect which is difficult to debug. The ID of the sent and
received messages will defer and it takes some time to debug the call hierarchy from
AmqpOutboundEndpoint.sendAndReceive() to AbstractHeaderMapper.getTransientHeaderNames() to understand why.
This is going to change as of Spring Integration 5.1 M1, see INT-4476 for more details. However a workaround is needed for the time being and I'm using Gary Russel's suggestion which makes use of message header enrichers.
Generating header values
public class EventHeadersValueGenerator {
private static final IdGenerator DEFAULT_ID_GENERATOR = new AlternativeJdkIdGenerator();
private static final Clock DEFAULT_CLOCK = Clock.systemUTC();
private final IdGenerator idGenerator;
private final Clock clock;
public EventHeadersValueGenerator() {
this(DEFAULT_ID_GENERATOR);
}
public EventHeadersValueGenerator(IdGenerator idGenerator) {
this(idGenerator, DEFAULT_CLOCK);
}
EventHeadersValueGenerator(
@NonNull IdGenerator idGenerator, @NonNull Clock clock) {
this.idGenerator = idGenerator;
this.clock = clock;
}
/**
* @param message isn't used; it was added for making this method usable with the Java DSL.
*/
public UUID createEventId(Message<?> message) {
return idGenerator.generateId();
}
/**
* @param message isn't used; it was added for making this method usable with the Java DSL.
*/
public Instant createEventTimestamp(Message<?> message) {
return Instant.now(clock);
}
}First part of solution is to provide a custom ID and TIMESTAMP generator. Note that I don't have to implement any
special interfaces or support classes provided by Spring Integration. As it's Java DSL fully embraces lambdas, I can
simply get away with providing createEventId and createEventTimestamp as function references at the right places.
Converting header values
Header values are simply converted to string with the underlying object's toString() method by
DefaultMessagePropertiesConverter.
For the forget-me app's purposes it's more important to render event timestamps' in a human readable format than
providing high storage efficiency, thus EventHeadersValueGenerator creates instances of java.time.Instant and that
ends up being serialized as an ISO Zulu timestamp (like 2018-04-05T14:30Z).
@Service
public class SubscriberServiceImpl implements SubscriberService {
...
@Override
@Transactional
@ServiceActivator(inputChannel = "webhookDataHandlerOutboundChannel")
public void updateSubscription(
@NonNull @Payload WebhookData webhookData,
@NonNull @Header(EVENT_TIMESTAMP) LocalDateTime eventTimestamp) {
...
}
...
}Eventually, I want to use the value of header EVENT_TIMESTAMP as a java.time.LocalDateTime, as it's going to be
persisted to the DB and here comes the interesting part. Everything which is annotated with @Header is subject to
being converted by Spring's converter infrastructure (Converter<Source, Target>). This is basically the same mechanism
which works under the hood when you're using Spring MVC and it shows a great deal of Spring's versatility.
@Configuration
@EnableIntegration
@RequiredArgsConstructor
public class IntegrationConfig implements InitializingBean {
private final BeanFactory beanFactory;
@Bean
public EventHeadersValueGenerator eventHeadersValueGenerator() {
return new EventHeadersValueGenerator();
}
@Override
public void afterPropertiesSet() {
Assert.notNull(this.beanFactory, "BeanFactory is required");
ConversionService conversionService = IntegrationUtils.getConversionService(this.beanFactory);
if (conversionService instanceof GenericConversionService) {
ConversionServiceFactory.registerConverters(
createConverters(),
(GenericConversionService) conversionService
);
} else {
Assert.notNull(
conversionService,
"Failed to locate '" + IntegrationUtils.INTEGRATION_CONVERSION_SERVICE_BEAN_NAME + "'"
);
}
}
private Set<Converter<?, ?>> createConverters() {
Set<Converter<?, ?>> converters = new HashSet<<();
converters.add(new StringToLocalDateTimeConverter());
converters.add(new InstantToLocalDateTimeConverter());
return converters;
}
}The only caveat here is that Spring Integration has got its own
ConversionService
and you need to register your custom converters with that.
Addressing pitfall #2: Poison Messages

As I mentioned earlier infinite redelivery of poison messages can be very harmful. You should know that Spring AMQP's message listener containers are configured by default in such a way that they requeue failed messages automatically.
Disable requeuing
Let me quote the pertinent JavaDoc from the source code of
AbstractMessageListenerContainer.
Set the default behavior when a message is rejected, for example because the listener threw an exception. When true, messages will be requeued, when false, they will not. For versions of Rabbit that support dead-lettering, the message must not be requeued in order to be sent to the dead letter exchange. Setting to false causes all rejections to not be requeued. When true, the default can be overridden by the listener throwing an
AmqpRejectAndDontRequeueExceptionDefault true.
On one hand, you could prevent this from happening by simply throwing AmqpRejectAndDontRequeueException, but bear in
mind that much higher level abstractions are being used here and we definitely don't want our service activators know
about AMQP or any other lower level component. That would defeat the purpose of using Spring Integration in the first
place. Instead, defaultRequeueRejected should be disabled and dead letter queues configured (see above).
Implementing retry
Spring Retry provides a great deal of flexibility to specify the parameters of the retry and Spring AMQP also provides a convenient form of retry for AMQP use cases.
Stateless retry
Stateless retry is appropriate if there is no transaction and it's simpler to configure and analyse than stateful retry.
See StatelessRetryInterceptorBuilder
for more details.
Stateful retry
Sstateful retry is appropriate if there is an ongoing transaction started higher up the stack which must be rolled back or definitely is going to roll back. Stateful retry needs a mechanism to uniquely identify a message. There are three options to do that
- Put a unique value into ID header of the message; we saw before that this won't come through by default. You'll have
to override transient header names in
DefaultAmqpHeaderMapperto do that. - Message converters can do this by setting
createMessageIds=true. - In case of custom message identifiers you can create a
MessageKeyGeneratorimplementation which must return a unique key for each message.
See StatefulRetryInterceptorBuilder for more details.
Conclusion
The devil is in the details. Even something as simple as sending and receiving messages with Spring Integration's AMQP support can be a challenging. That said, there are three things I'd recommend you doing.
- Do use dead lettering - In RabbitMQ Dead letter exchanges (DLXs) are normal
exchanges. To set the dead letter exchange for a queue, set the
x-dead-letter-exchangeargument to the name of the exchange - Disable requeueing - Don't rely on the default behaviour of AMQP message listener container and set
defaultRequeueRejected = false - Be careful with stateful retry - Only does it work well, when messages are identifiable properly.
Next in this series
The application's architecture is modular in that sense that it supports arbitrary number of data provider support modules. From this point of view, a part of the message flow (up to the message router and from the subscription inbound channel) is common and a part of it (containing provider specific message transformers and service activators) is internal to individual support modules. In the third part, we'll explore what technical challenges this modular design raises and how they can be tackled by using child application contexts for registering sub-flow dynamically.
Join my Newsletter
If you like Java and Spring as much as I do, sign up for my newsletter.